
Inserire tutti i criteri desiderati: saranno cercate le app che li soddisfano tutti; se si specifica più volte lo stesso criterio, solo l'ultima occorrenza sarà considerata.
 Una volta cliccato sulla voce “Guarda la demo” apparirà la seguente schermata. Questo servizio permette, partendo da un testo, di generare dei file audio con una cadenza e un’intonazione appropriate alla lingua scelta. È disponibile in 27 voci (13 neurali e 14 standard) in 7 lingue; per avere un audio con una voce naturale è consigliabile utilizzare le voci neurali (V3, enhanced dnn). Le voci selezionate offrono funzioni di sintesi espressiva (SSML) e di trasformazione della voce. La lingua in cui è stato scritto il testo deve corrispondere alla lingua della voce che è stata selezionata, altrimenti lingua del testo e lingua della voce diverse non produrranno risultati non corretti nella pronuncia. Il file audio generato verrà restituito in un file mp3 che potrà essere riprodotto tramite lettori VLC e Audacity.
Una volta cliccato sulla voce “Guarda la demo” apparirà la seguente schermata. Questo servizio permette, partendo da un testo, di generare dei file audio con una cadenza e un’intonazione appropriate alla lingua scelta. È disponibile in 27 voci (13 neurali e 14 standard) in 7 lingue; per avere un audio con una voce naturale è consigliabile utilizzare le voci neurali (V3, enhanced dnn). Le voci selezionate offrono funzioni di sintesi espressiva (SSML) e di trasformazione della voce. La lingua in cui è stato scritto il testo deve corrispondere alla lingua della voce che è stata selezionata, altrimenti lingua del testo e lingua della voce diverse non produrranno risultati non corretti nella pronuncia. Il file audio generato verrà restituito in un file mp3 che potrà essere riprodotto tramite lettori VLC e Audacity. 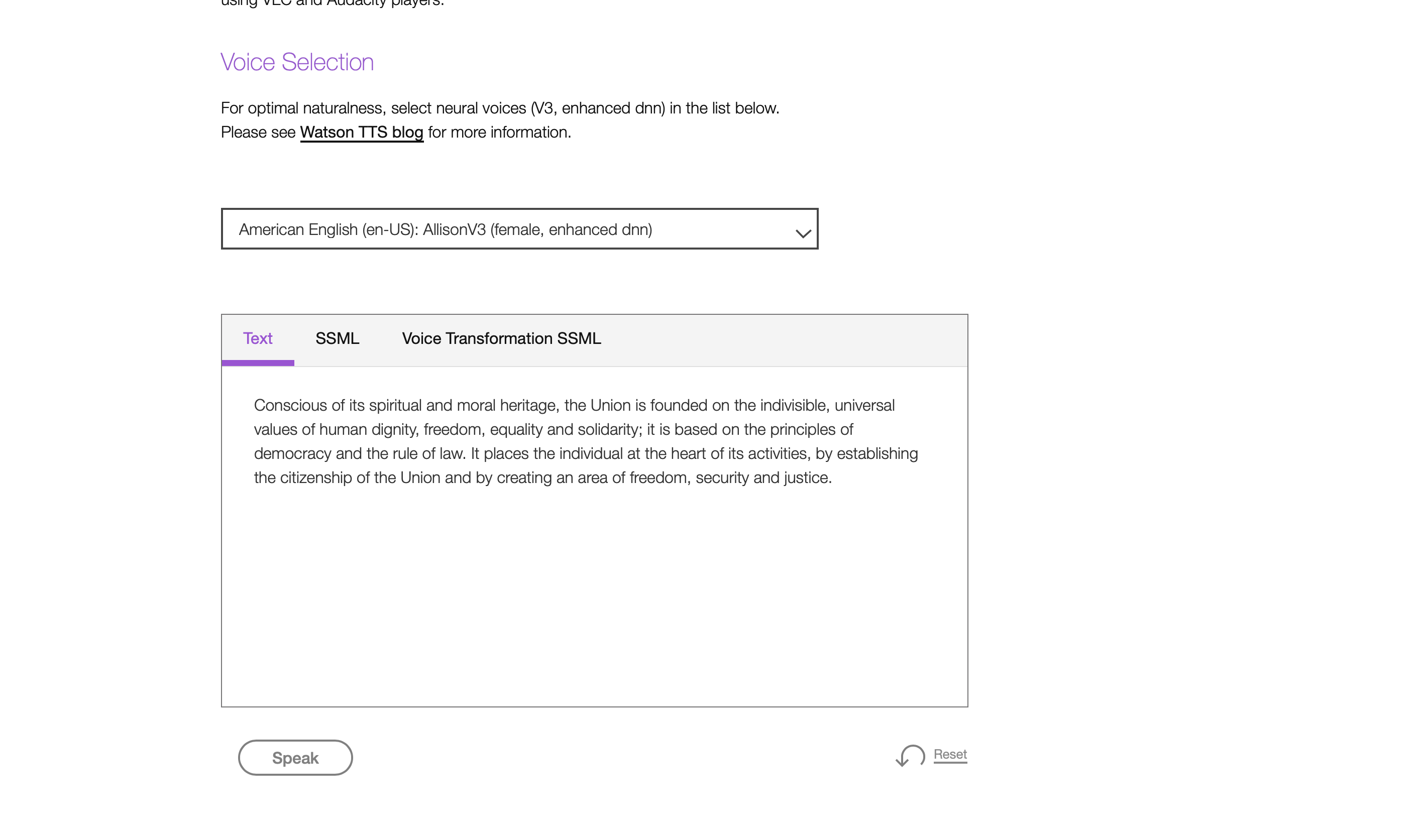 Quindi dopo aver inserito il testo sarà necessario cliccare sul tasto “speak”, in questo modo sarà possibile sentire l’audio relativo al testo scritto. Dopodichè se si vuole scaricare l’audio sarà sufficiente cliccare con il tasto destro del mouse su di esso e scegliere l’opzione “copia l’indirizzo dell’audio”, aprirlo in un’altra finestra del browser e poi effettuarne il download.
Quindi dopo aver inserito il testo sarà necessario cliccare sul tasto “speak”, in questo modo sarà possibile sentire l’audio relativo al testo scritto. Dopodichè se si vuole scaricare l’audio sarà sufficiente cliccare con il tasto destro del mouse su di esso e scegliere l’opzione “copia l’indirizzo dell’audio”, aprirlo in un’altra finestra del browser e poi effettuarne il download. 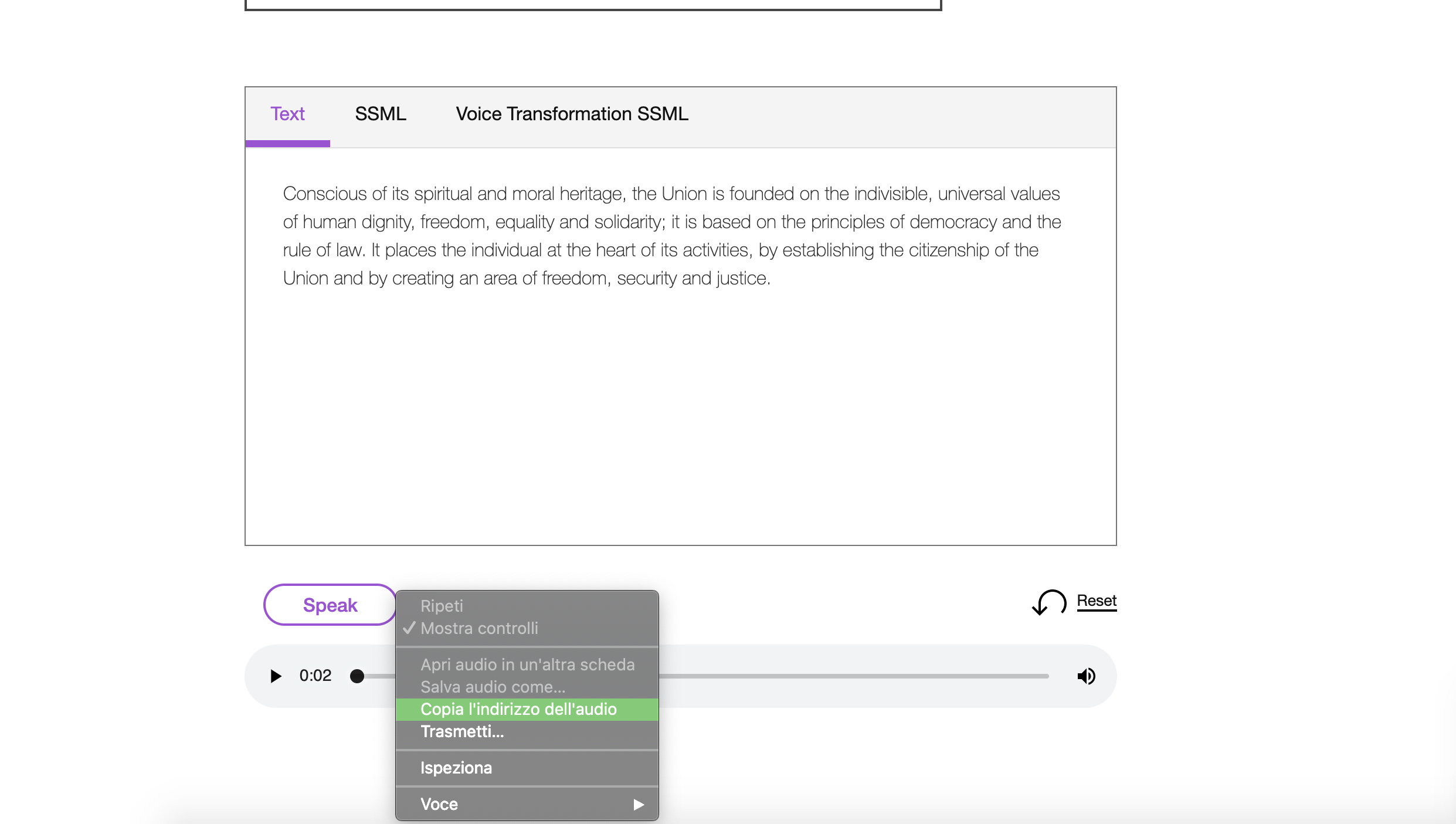 Come indicato precedentemente, le voci selezionate offrono funzioni di sintesi espressiva (SSML). Lo Speech Synthesis Markup Language è un linguaggio standard di markup che permette di controllare, nella sintesi vocale, pronuncia, volume, tono, velocità, inserire pause, ecc.Per esempio nella schermata che segue è possibile notare che è stato inserito l’elemento “break” associato all’attributo “time” che indica una determinata lunghezza della pausa che può essere espressa in secondi o in millisecondi; un altro esempio è l’inserimento dell’elemento “prosody”, che controlla il tono, la velocità di pronuncia e il volume del testo, a cui è stato associato l’attributo “rate” che indica un cambiamento di velocità nella pronuncia del testo. Il servizio SSML offre, inoltre, la possibilità di utilizzare altri elementi: come l’utilizzo di SSML di espressività (modo in cui il testo deve essere espresso quando viene pronunciato), l’utilizzo di SSML per la trasformazione della voce e l’inserimento di fonemi per specificare l’ortografia fonetica utilizzata per pronunciare una parola. Per definire la pronuncia fonetica di una parola si deve utilizzare l’elemento
Come indicato precedentemente, le voci selezionate offrono funzioni di sintesi espressiva (SSML). Lo Speech Synthesis Markup Language è un linguaggio standard di markup che permette di controllare, nella sintesi vocale, pronuncia, volume, tono, velocità, inserire pause, ecc.Per esempio nella schermata che segue è possibile notare che è stato inserito l’elemento “break” associato all’attributo “time” che indica una determinata lunghezza della pausa che può essere espressa in secondi o in millisecondi; un altro esempio è l’inserimento dell’elemento “prosody”, che controlla il tono, la velocità di pronuncia e il volume del testo, a cui è stato associato l’attributo “rate” che indica un cambiamento di velocità nella pronuncia del testo. Il servizio SSML offre, inoltre, la possibilità di utilizzare altri elementi: come l’utilizzo di SSML di espressività (modo in cui il testo deve essere espresso quando viene pronunciato), l’utilizzo di SSML per la trasformazione della voce e l’inserimento di fonemi per specificare l’ortografia fonetica utilizzata per pronunciare una parola. Per definire la pronuncia fonetica di una parola si deve utilizzare l’elemento 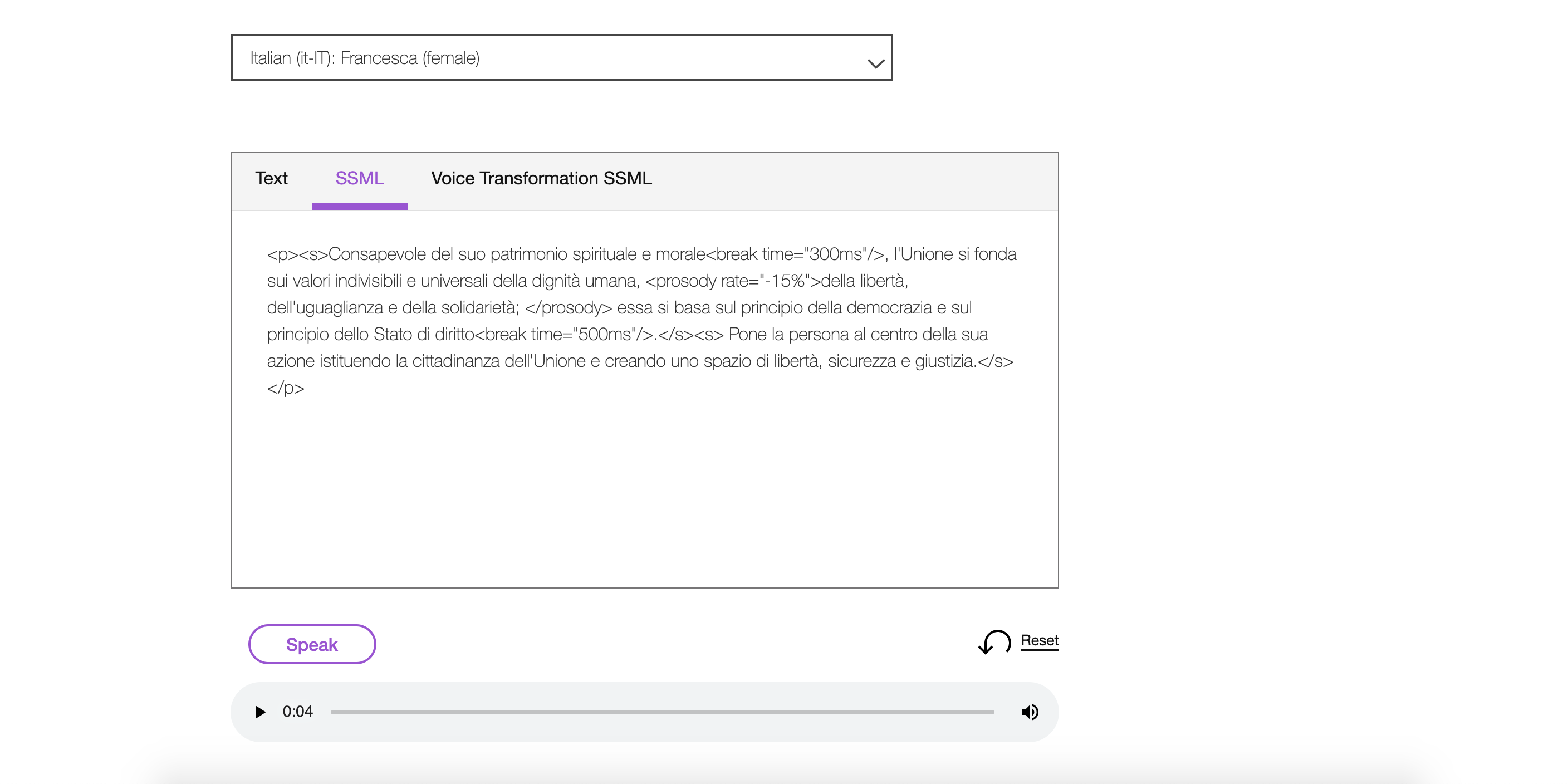 Per quanto riguarda l’utilizzo di SSML per la trasformazione della voce questo ci permette di espandere la gamma delle voci tramite l’elemento
Per quanto riguarda l’utilizzo di SSML per la trasformazione della voce questo ci permette di espandere la gamma delle voci tramite l’elemento 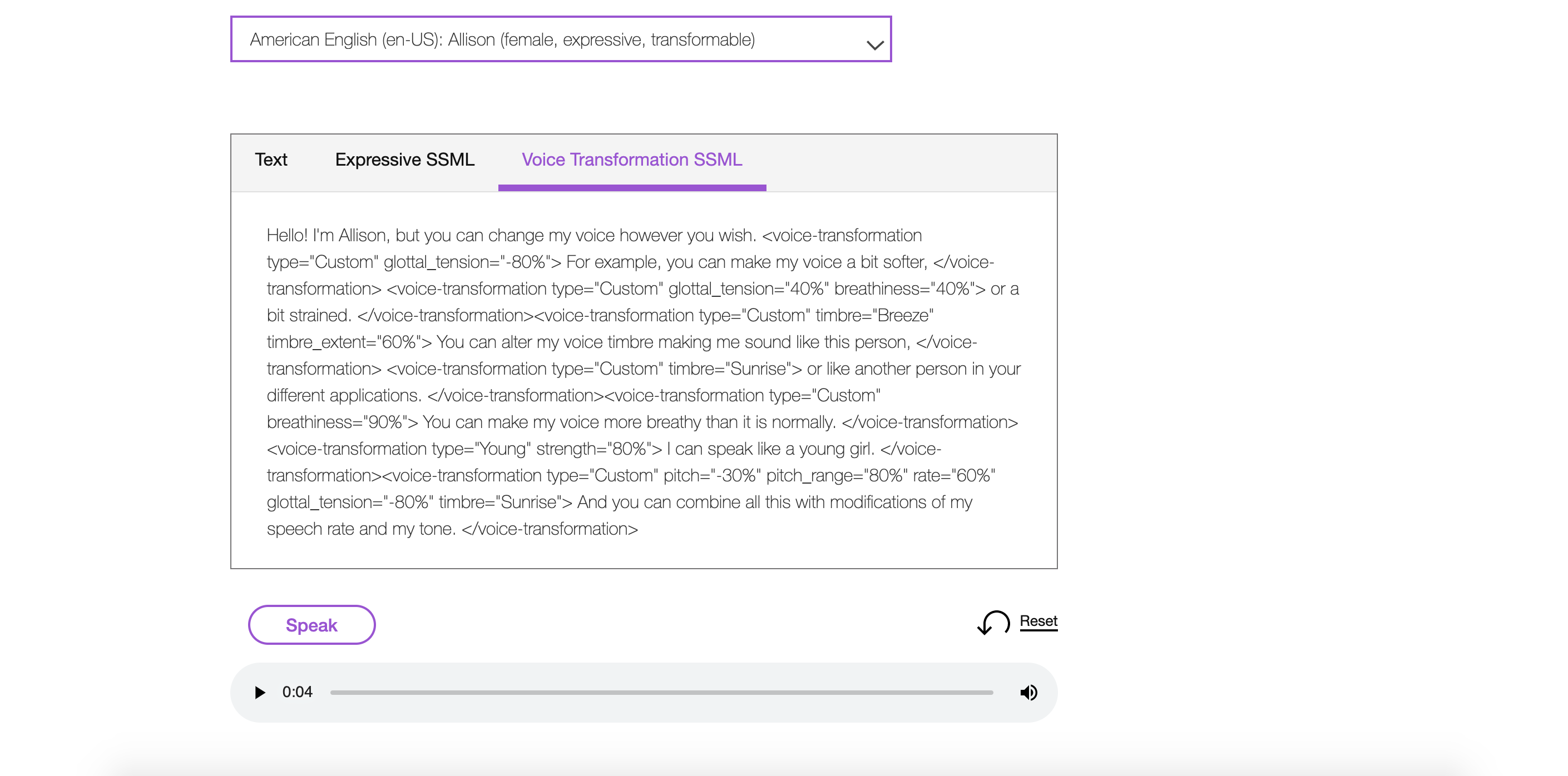





Copia link